
EFT High Availability (HA)
With active-active configuration and horizontal scalability, you can maximise your network uptime. When you bring a node down for upgrades or patches, the other nodes continue to process transactions, meeting those stringent uptime requirements.
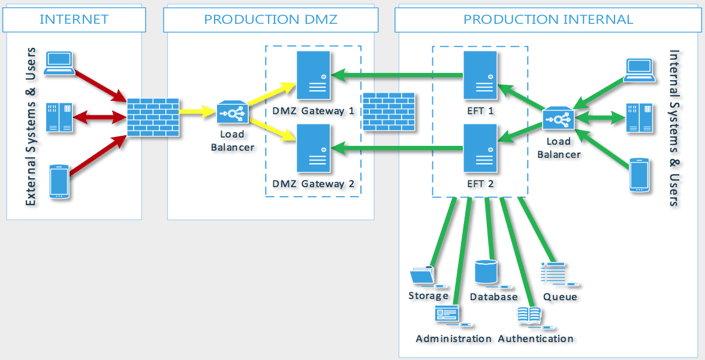
EFT’s active-active deployment provides HA using multiple EFT servers and a load balancer, for non-stop availability of your network. And unlike active-passive failover clusters, all of the nodes in EFT’s active-active deployment are put to work in production–with no standby hardware, and no clustering software. For true business continuity you should have a minimum of three nodes, which allows you to bring down one node for maintenance without losing fault tolerance. The other two nodes can continue to process files while the inactive node is updated/repaired.
Active-Active Layout
Why EFT HA?
- Highly available, “always on” service for maximising uptime
- Horizontal scalability to support larger file transfer and event rule processing workloads
- Message queuing keeps all nodes in syncEasily manage your entire HA cluster through a single admin instance, with no limit on how many nodes can be added.
- Easily manage your entire HA cluster through a single admin instance, with no limit on how many nodes can be added.
- Works with industry-standard load balancers
- No cluster-management software required—EFT does that internally
Key Features
Easy Installation
The EFT installer provides built-in configuration to support a highly available, active-active deployment. In the installation wizard, you can specify that you are installing EFT in an active-active cluster, and then configure options such as a shared storage location. Command-line or “silent” installation is also available.
Easy Configuration
EFT’s administrator can perform administration and configuration for every node on just one of the nodes. Messages are forwarded to all other nodes using message queues as reliable, asynchronous transport, and EFT acts on the messages in the queue by processing them locally.
Coordinated Automated Workflows and Event Processing
Automated workflows and events are coordinated between nodes to provide highly available automation. The administrator designates load balancing of the event rule processing and specifying failover nodes for event triggers.